Инструмент для нагрузочного тестирования Gatling по сути своей является фреймворком, имеющим свою standalone реализацию или же интегрирующийся в существующий проект. Данный инструмент полностью написан на Scala (усовершенствованном аналоге языка Java), в основе которого лежат такие технологии как Akka и Netty, что говорит о больших возможностях и высокой производительности этого инструмента, а также открывает нам доступ ко всем преимуществам JVM. Из коробки Gatling поддерживает несколько протоколов, к примеру, HTTP, Websocket, что позволяет тестировать различного типа веб-приложения. Для анализа результатов Gatling может как сам генерировать html-отчеты, так и интегрироваться с различными инструментами мониторинга.
В этой статье я приведу обзор инструмента, возможные варианты установки и пример простого нагрузочного скрипта.
Подсказка: Автор: Юнусов Акмаль, инженер по нагрузочному тестированию в Bell Integrator.
Возможности инструмента
Gatling является универсальным инструментом нагрузочного тестирования и обладает немалыми возможностями. Главной его особенностью является то, что написание скриптов происходит на языке Scala, что подразумевает работу на JVM. Но разработку скриптов можно производить также на языках Java и Kotlin. Gatling не имеет графического интерфейса, вся разработка ведется исключительно путем написания кода. При том для создания скриптов в Gatling нет необходимости хорошо знать Scala или Java, ведь у Gatling имеется DSL (предметно-ориентированный язык), поняв концепцию и изучив основные функции которого, можно относительно быстро приступить к работе.
Концепция генерации виртуальных пользователей у Gatling несколько отличается от, например, Jmeter, где пользователи генерируются в виде потоков. Здесь же пользователи генерируются в виде сообщений благодаря фреймворку Akka, в основе которого лежит модель акторов. Такой принцип может обеспечить гораздо больший объем пользователей в сравнении с принципом потоков при тех же аппаратных ресурсах.
Для записи сценариев у Gatling имеется свой Gatling Recorder, который выступает в качестве HTTP-прокси или может использоваться как HAR-конвертер. Используя записанные HAR-файлы, можно преобразовать их в готовый скрипт. Рекордер поставляется вместе с Gatling в виде скриптов recorder.bat или recorder.sh.
Из коробки Gatling не поддерживает распределенное тестирование. Режим кластеризации доступен в корпоративной версии Gatling Frontline. Но существует способ запуска скриптов на нескольких машинах через shell-скрипты и ssh-подключение.
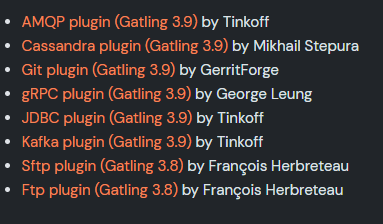
Как и большинство инструментов для нагрузочного тестирования Gatling поддерживает основной стек веб-протоколов. Среди них HTTP, TCP, FTP, JMS. Также Gatling имеет множество различных методов и сравнительно широкие возможности при работе с WebSocket. Например, в сценарии работа с WebSocket и HTTP может осуществляться параллельно, а также при необходимости возможно использовать данные, полученные из WebSocket в ветке с HTTP-запросами. Помимо веб-протоколов Gatling поддерживает работу с БД через JDBC-протокол. В расширенной версии Gatling Enterprise есть поддержка протокола MQTT. С помощью официальных плагинов, разработанных проверенными источниками, можно кратно увеличить возможности инструмента. Ниже приведены некоторые из них:
Для работы с внешними источниками данных в Gatling есть специальный метод feed, принимающий в себя объект feeder (https://gatling.io/docs/gatling/reference/current/core/session/feeder/). Фидером может выступать как коллекция, текстовый файл, json-объект, так и прямой запрос в БД через JDBC или чтение из Redis.
Благодаря инструментам автоматизированной сборки Gatling-проект может быть запущен в автоматизированном порядке и добавлен в CI/CD пайплайны Jenkins, TeamCity, GitLab и т.п. У Jenkins также имеется плагин для работы с результатами тестов, он может предоставлять тренды результатов от сборки к сборке.
Далее рассмотрим способы установки Gatling и напишем небольшой скрипт.
Установка и первый скрипт
Способов интеграции Gatling существует несколько, но любой из них предполагает, что в системе установлена JDK (как минимум JDK8):
1. Gatling возможно установить в качестве отдельного пакета. Для написания скриптов понадобится лишь текстовый редактор, а для запуска используется командная строка. Скачать пакет можно с официального сайта (https://gatling.io/open-source/). Структура директорий пакета имеет свою иерархию:
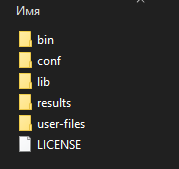
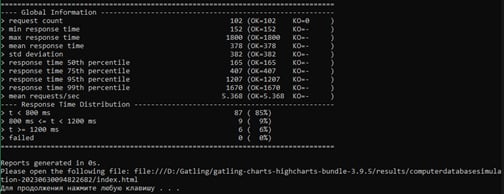
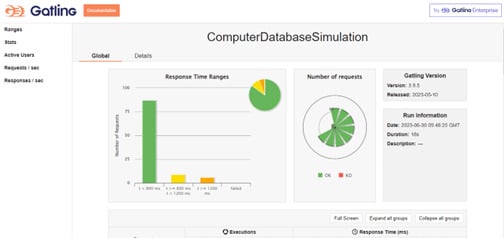
— bin: пробный скрипт Gatling и скрипты рекордера. Запустив gatling.bat/.sh, будет запущен тест ComputerDatabaseSimulation для демонстрации, в папке results будет сформирован демонстрационный отчет.
— conf: конфигурационные файлы Gatling, Akka и Logback.
— lib: бинарные файлы Gatling и зависимостей.
— user-files:
simulations: здесь будут находится скрипты симуляций.
resources: файлы с неисходным кодом (фидеры, шаблоны запросов и т.п.).
lib: сюда можно добавить свои jar-файлы зависимостей.
— results: сюда генерируются результаты тестов.
Пакетная версия Gatling поддерживает написание скриптов на Java и Scala.
1. Интеграция в проект с помощью инструментов сборки.
Официальный сайт Gatling предлагает демо-проекты, написанные на Java, Kotlinи Scala как с использованием maven, так и с gradle. С помощью этих инструментов также можно запускать скрипты из командной строки. Их можно скачать с GitHubи использовать как основу для проектов.
В случае использования IDE Intellij Idea необходимо установить в нее Scala-плагин, так как из коробки IntelliJ поддерживает только Java и Kotlin. Сделать это можно следующим образом:
После установки можно писать скрипты на Scala и использовать SBT.
Чтобы интегрировать Gatling в проект, нужно добавить следующие зависимости в pom.xml:
Или в build.gradle:
SBT (Scala build tool) плагин.
Для работы со скриптами Gatling с помощью SBT также можно скачать демонстрационный проект (https://github.com/gatling/gatling-sbt-plugin-demo), либо добавить Gatling-плагин в project/plugins.sbt:
Затем добавить зависимости и включить Gatling в build.sbt:
Теперь на примере maven-проекта на Java напишем небольшой скрипт, в котором будут затронуты основные функции, используемые в типовом скрипте для нагрузки HTTP-сервиса. В качестве тестируемого объекта выступит сайт, разработанный командой Gatling специально для обучения (https://computer-database.gatling.io/computers).
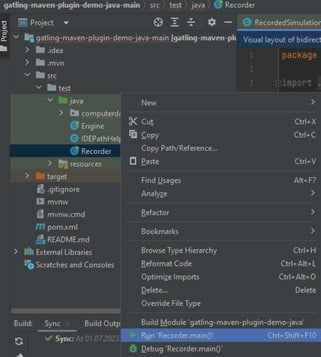
1. Начнем с записи запросов. Открываем проект в IntelliJ Idea, находим файл Recorder и запускаем его:
2. Откроется окно рекордера. Здесь необходимо указать некоторые настройки:
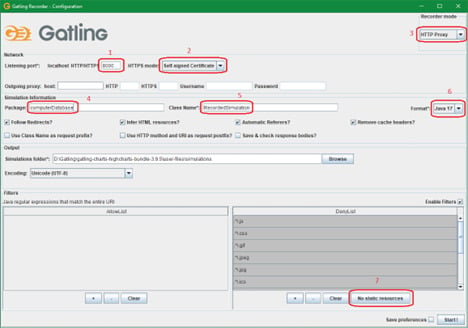
— Указать порт прокси-сервера.
— Указать настройки сертификата
— Выбрать режим записи HTTP-прокси или HAR-конвертер.
— Имя пакета.
— Имя генерируемого скрипта.
— Выбрать язык генерации скрипта.
— Нажать, чтобы отфильтровать запросы со статическими файлами.
3. Теперь нужно настроить локальный прокси-сервер:
Открываем параметры браузера (в нашем случае Google Chrome)
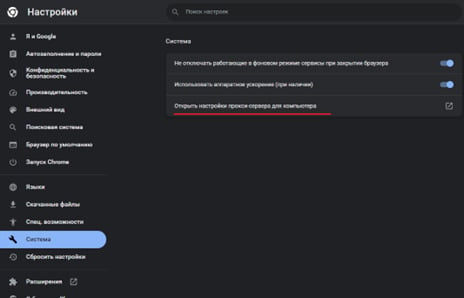
Далее откроются параметры системы. Необходимо указать следующие параметры и нажать «сохранить»:
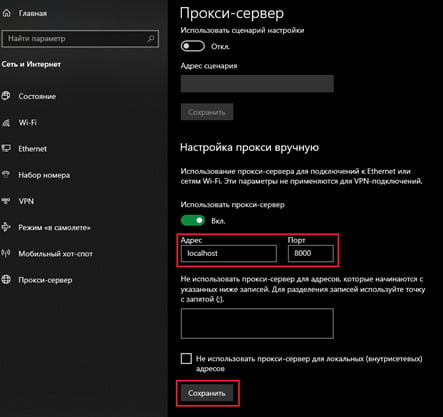
Теперь в окне рекордера нажать «Start!». Начнется запись. Далее появится окно:
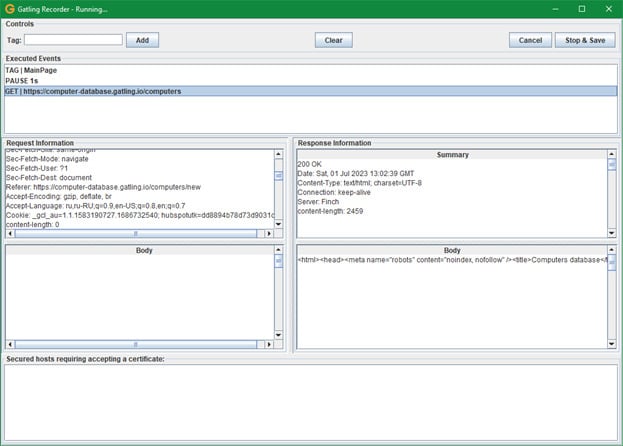
В поле Tag можно указать наименования бизнес-операций. Например, здесь транзакция открытия главной страницы имеет название MainPage.
Запишем сценарий, состоящий из следующих транзакций, попутно расставляя тэги:
1 — Открытие главной страницы
2 — Заполнение строки поиска
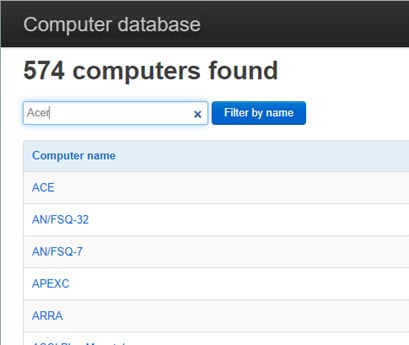
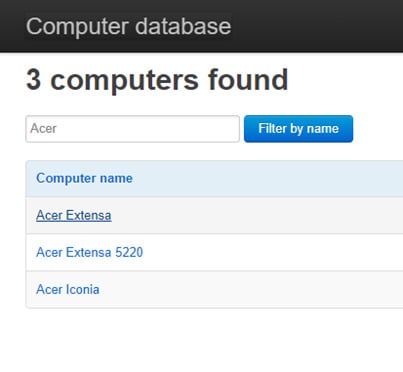
3 — Выбор результата поиска
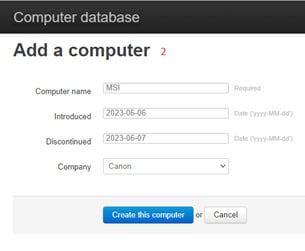
4 — Создание компьютера в базе данных с заполнением полей
4. После окончания этих шагов необходимо нажать Stop&Save. Затем в папке проекта появится пакет с указанным названием и скриптом внутри него.
5. Открываем записанный нами скрипт и чистим его от всех хэдеров (объекты с названием header-x) и их упоминаний.
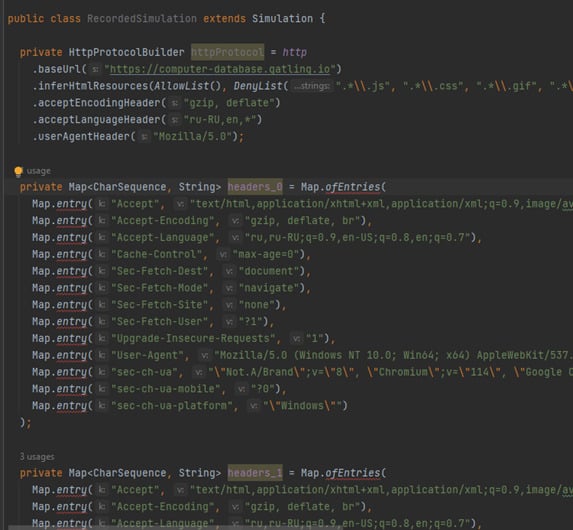
6. В результате имеем следующее:
Данный скрипт состоит из трёх частей:
Данные о протоколе подключения
Записанные запросы с параметрами
Параметры симуляции
Сейчас наши запросы никак логически не разграничены, для удобочитаемости и модульности проекта необходимо разграничить их на блоки, характеризующие те или иные бизнес-операции. Для этих целей нам понадобится объект класса ChainBuilder, куда необходимо поместить наши запросы. Также необходимо дать корректные названия нашим запросам:
Наш сценарий scn не включает в себя какие-либо транзакции. Создадим два сценария — сценарий пользователя и сценарий администратора. Они будут включать в себя разную комбинацию транзакций. Также добавим в наши блоки think таймы с помощью метода pause().
Теперь у нас есть два сценария: сценарий пользователя с открытием главной страницы и поиском компьютера, сценарий администратора с открытием главной страницы и созданием компьютера. Сделаем наш скрипт более динамичным. Добавим объект feeder, названия компьютеров мы будем читать из csv-файла. Имеем файл search.csv, в котором перечислены поисковые запросы и наименования компьютеров:
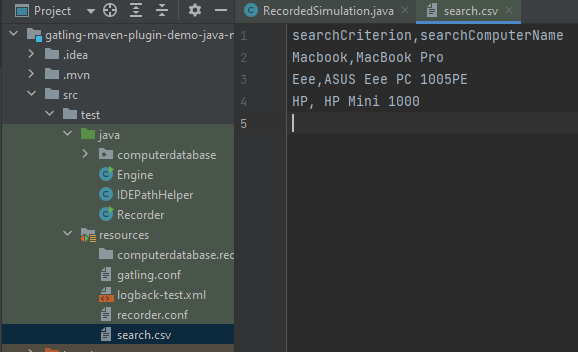
Создаем объект feeder:
В csv(«search.csv») необходимо указать путь к файлу. С помощью .circular() указываем, что файл будет читаться построчно и по достижению конца будет читаться заново.
Добавим наш feeder в транзакцию с поисковым запросом и укажем имя столбца, из которого необходимо читать строки. Важно, чтобы вызов метода feed происходил раньше самого заброса:
Также нужно обратить внимание, что в .get(«/computers/330″) последний параметр запроса является результатом поиска. И при разных поисковых запросах этот параметр будет отличаться, поэтому нужно скоррелировать его.
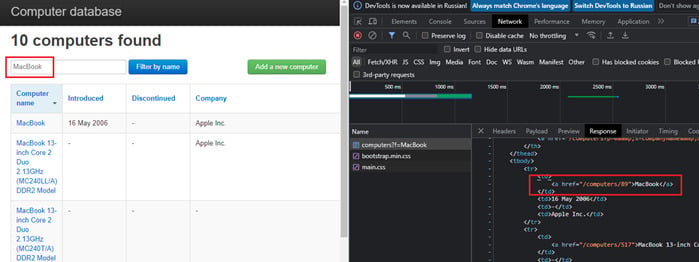
Доставать это значение будем из респонса предыдущего запроса с помощью метода check(). В метод check() передадим css-селектор с параметризированным в нем названием компьютера:
В метод check можно передать css-селектор, XPath, JsonPath и RegEx. Полученное значение сохраняем в параметр computerURL и передаем в следующий get запрос.
Следующим шагом будет параметризация полей при создании нового компьютера. Создадим файл, в котором запишем параметры:
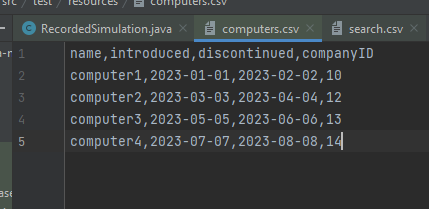
Создадим фидер и параметризируем поля запроса:
Наш скрипт параметризирован, скоррелирован и готов к запуску. Далее необходимо указать настройки симуляции. Добавим в симуляцию скрипт администратора, укажем количество виртуальных пользователей и тайминги:
Здесь injectOpen/injectClosed — это методы, характеризующие модель нагрузки — открытую и закрытую. Для сценария пользователя прописали, что виртуальные пользователи будут выходить в количестве 15 штук в течение 10 секунд. Для сценария администратора — постоянное количество активных пользователей в течение 10 секунд. В метод protocols передали конфигурацию протокола, указанную выше.
Запустим наш скрипт maven командой из командной строки:
здесь computerdatabase — имя пакета, RecordedSimulation — имя скрипта
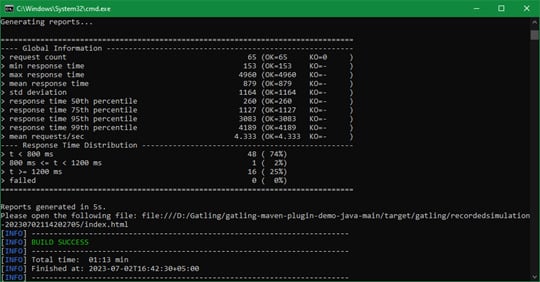
В папке target/gatling/ сохранены результаты тестов. Переходим в папку с последним запуском и открываем файл index.html.
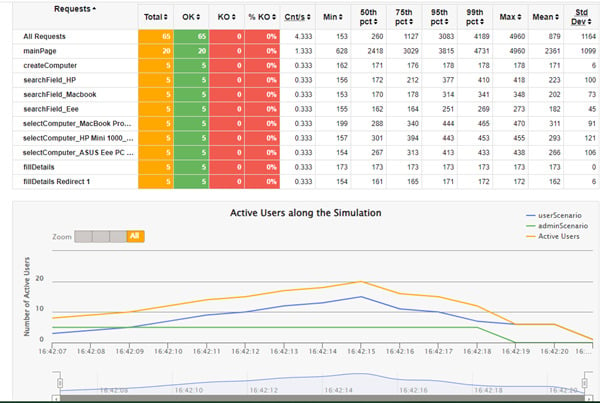
Таким образом, мы написали наш первый простейший скрипт с помощью фреймворка Gatling. Так как статья носит обзорный характер, мы не стали углубляться в Gatling Java DSL, это потребует написания отдельного практического руководства.
Напоследок в качестве примера интеграции с системами мониторинга мы настроим передачу метрик из Gatling в InfluxDB+Grafana.
Откроем файл конфигурации gatling.conf, он находится в resources/gatling.conf. Отправка метрик будет происходить по протоколу Graphite. Ниже нужно указать порт, который слушает Graphite:
В нашем примере мы будем использовать InfluxDB 1.8. Откроем файл конфигурации и также раскомментим плагин graphite. Обязательно нужно указать имя базы данных и template метрик
Далее нужно запустить InfluxDB из командной строки и создать базу данных gatlingdb
Убедимся, что Graphite запустился
Создаем datasource InfluxDB в Grafana и добавляем панель, к примеру панель активных пользователей:
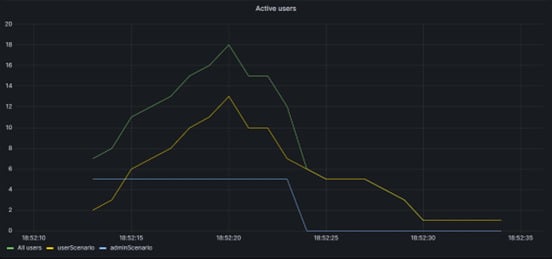
Аналогичный график из отчета Gatling
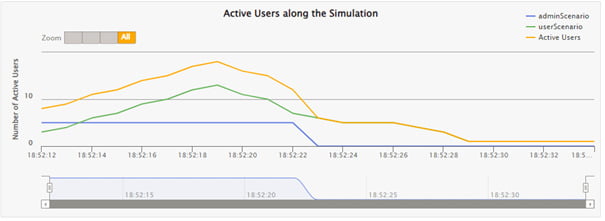
Итак, подведем итоги. Проведя тестирование возможностей инструмента, мы можем выделить следующие его преимущества — производительность, широкие возможности интеграции в различные проекты и в циклы CI/CD, открытый исходный код, возможность написания своих плагинов и работа над скриптами в команде, возможность интеграции с системами мониторинга. Но у Gatling есть и несколько недостатков — написание скриптов все же требует базовых навыков программирования и знания DSL, следовательно, потребуется некоторое время для обучения инструменту. Кроме того, из коробки Gatling поддерживает относительно небольшое количество протоколов.
Список используемых источников
3. Официальная документация Gatling
4. Документация об акторах Akka
6. InfluxDB
7. Grafana



Добавить комментарий