Эта статья – часть цикла про “5 ETL для зоопарка ботов”:
Вот предыдущие статьи:
— Анонс цикла с перечнем технологий
— Настройка потока логов «Из Dialogflow в BigQuery»
Допустим, вы создаете ботов и получили достаточно диалогов, чтобы появилась потребность автоматизировать их аналитику. Это спектр задач Data Analyst, и если вы планируете освоить эту профессию, или просто хотите автоматизировать аналитику, эта статья для вас.
В ней я покажу, как создавать запросы с помощью BigQuery API – клиентской библиотеки, упрощающей обращение с хранилищем. Из стандартной четверки действий CRUD (create, read, update, write) сегодня мы познакомимся с чтением (“read”) и записью (“write”). На остальные дам ссылки. Я исхожу из предпосылки, что вы уже знаете, как настроить поток пользовательских данных из конструктора в хранилище данных. Если нет, прочитайте вторую статью.
Установка gcloud CLI
Google может себе позволить усложнить процедуру авторизации, так что процесс подключения в первый раз занял у меня несколько часов. Все последующие попытки занимают не более 15 минут.
Для демонстрации я использую Visual Studio Code, однако если вы затрудняетесь с выбором среды разработки, рекомендую свою статью про IDE с лучшим UI / UX.
Чтобы подключаться к базе со своего компьютера, прежде всего необходимо скачать дистрибутив gcloud CLI – утилиту для управления продуктами Google с помощью командной строки. Например, для Linux можно использовать curl.
Скачайте дистрибутив в корневую папку системы:
Затем, пребывая в той же директории, распакуйте архив:
Запустите установку пакета:
Установка необходимых инструментов Google завершена. Теперь пройдем процедуру авторизации.
Авторизация в Google Cloud
Поскольку сервисы компании периодически пытаются взламывать, то простым Bearer Token (“токен на предъявителя”: скопировал с консоли и вставил в код) уже не обойтись. Поэтому нам предстоит авторизоваться под своим аккаунтом, затем выбрать проект и сгенерировать локальную копию ключей доступа.
Инициируем экземпляр gcloud CLI:
Система переадресует нас на веб-страницу авторизации Google или выдаст копируемую ссылку в командной строке (на случай работы в операционных системах без графического интерфейса, как серверный Linux). После ввода пароля и подтверждения с помощью авторизованного устройства возвращаемся в командную строку.
Теперь система спрашивает, к какому проекту привязываться при обращении к базе данных:
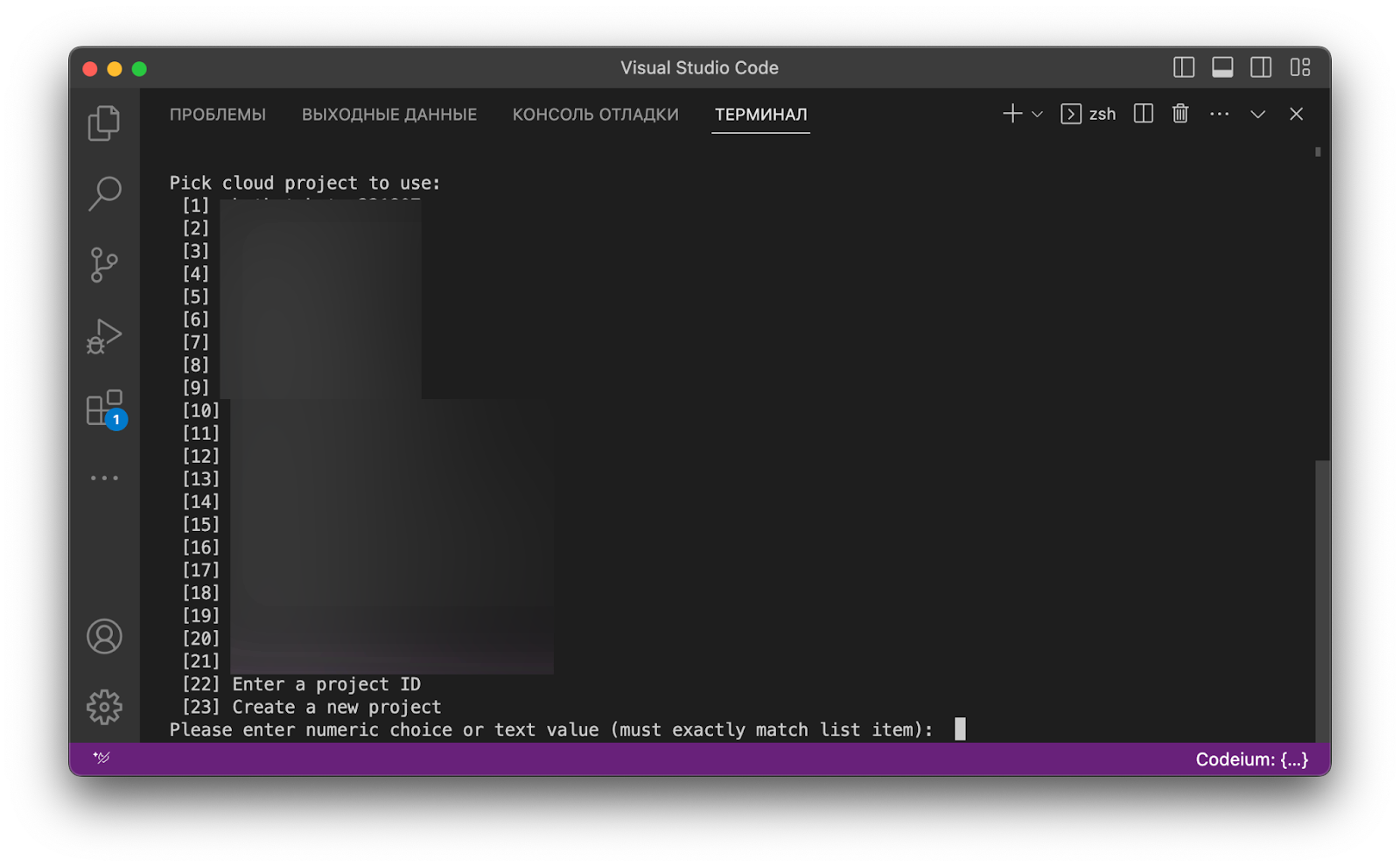
Введя число, мы звершаем стадию подключения проекта. Дело за малым — сгенерировать ключи:
Команда выше кладет в корневую директорию системы такой JSON-файл:
Его в репозиторий с кодом лучше не заливать из соображений безопасности.
Подсказка: Если вы обратили внимание, в JSON-файле присутствует refresh_token – это означает, что привычные нам токены имеют здесь срок годности, и с этим файлом ключей можно автоматически продлевать доступ к Google Cloud. Указывать путь этого файла в скрипте.py не понадобится: gcloud CLI сам знает, где его взять.
При создании этого раздела я руководствовалась официальной документацией.
Верстка запроса
Настало время для самого интересного: обращение к данным хранилища BigQuery с помощью кода на Python. Для этого в выделенной директории (в идеале, репозитории) создадим скрипт count_daily_replicas.py.
Для начала импортируем необходимые библиотеки:
Затем зададим проект. Эту строку считаю атавизмом, ведь при авторизации в Google Cloud указала проект:
Теперь составим многострочный запрос, подсчитывающий число реплик за день:
Подсказка: За примерами запросов типа update, delete обращайтесь к базе примеров в документации.
Подсказка: Обращаю ваше внимание: dialogflow_agent_* — это так называемые wildcard-таблицы, В каждой из них лежит вложенный датафрейм за каждый день. Звездочкой обозначается коллекция за два месяца:
Таким образом, мы обратимся к базе и преобразуем результат в датафрейм:
Напомню, бесплатно Logs Router хранит и передает сессии за два предыдущих месяца, начиная с текущего момента. Потому в результате мы увидим выборку – 5 дней с начала интервала, и пять после. Всего 63 ряда:
Последний шаг – инъекция результата в хранилище:
Теперь, если вы подключите к этому процессу VPS (виртуальный частный сервер), то сможете запускать скрипт, скажем, раз в два месяца.
Для этого на малых объемах я использовала стандартную для Linux утилиту crontab. Клонировав на сервер репозиторий с таким кодом, просила Кронтаб запускать мой скрипт раз в два месяца. Покажу, как это сделать.
Откроем vim’ом редактор регулярных скриптов:
Вставляем такую строку:
Это означает, что 30-го числа в 03:30 ночи по местному для сервера времени (порой это важно), каждый второй месяц будет исполнятся скрипт.
В count_daily_replicas.sh вставим всего одну строку. Этот файл нужен crontab’у:
Важный нюанс: обоим файлам, и .py, и .sh, нужно разрешить быть исполненными системой. Делать это можно и на своем компьютере (где ведется разработка): сведения о правах доступа записываются как часть коммита:
Заключение
Теперь вам доступна вся мощь этих потрясающих инструментов! На мой взгляд, это первый шаг к по-настоящему автоматической отчетности, причем даже в случае с большими данными (BigQuery заточен под них).
На текущий момент вы умеете уже немало из компетенций дата-аналитика:
— составлять SQL-запрос;
— настраивать Google Cloud;
— пользоваться BigQuery API.
В следующей статье я покажу, как из запросов: представлений, CTE и других зверей из мира SQL собрать автообновляемый отчет в Google Looker (ex Data Studio).



Добавить комментарий