Представьте: вам как Python-разработчику доверили написать бота, но с чего начать?
Подсказка: Это статья из цикла «5 ETL для зоопарка ботов». В нём я пошагово разбираю, как наладить потоки данных из разных библиотек и конструкторов ботов на разных языках и стеках. В основе лежат Python и его библиотеки. Вот предыдущие статьи цикла:
— Анонс цикла с перечнем технологий
— Настройка потока логов «Из Dialogflow в BigQuery»
— Python для аналитики ad hoc из BigQuery
— Развертывание Airflow
— Настройка первого DAG
Если Вы уже знаете, как исполнять в коде SQL-запросы, понимаете основы ЯП достаточно, чтобы писать несложные программы, то бот может стать вашим следующим этапом профессионального развития: он позволит закрепить основы и связать их воедино. В дополнение ко всему, автоматизация рабочего процесса станет бонусом вам или вашим коллегам.
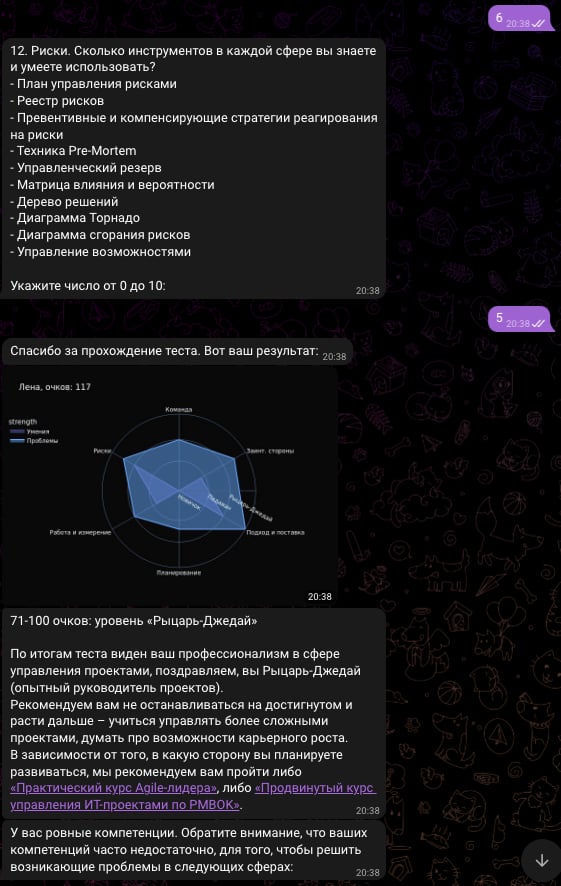
Мы получим довольно простого бота, который задаёт будущим студентам курса вовлекающие вопросы и оценивает навык управления проектами. И выводит:
— количество очков (рассчитывается по нелинейной формуле);
— график-паутинку на базе очков;
— индивидуальную рекомендацию курсов.
Запуск бота
Подключаем aiogram. Это фреймворк, а значит, взаимосвязанных скриптов в проекте немало:
Чтобы сервер понимал, с какого именно файла начать, в main.py добавляем условие if __name__ == ‘__main__’:
Подсказка: Поллинг (start_polling) — базовый способ «выпустить» бота в мир. Существует еще и вебхук-бот, но для его развёртывания требуется доменное имя, которому можно добавить A-запись, так что пока обойдемся простейшим решением.
В loader.py прописываем основные конфиденциальные настройки, которые будет брать бот:
Здесь указано, где брать токен, какой режим парсинга текста использовать и так далее.
Кстати, если вы еще не взаимодействовали с @BotFather и не создали своего бота, то отправьте ему /start, затем /newbot и проследуйте стандартным шагам. Подробнее в этом гайде.
Пишем модуль settings, из которого потом будем брать токен:
os.getenv() ссылается на некоторые переменные вроде TELEGRAM TOKEN и DATABASE. Их мы поместим в отдельный локальный файл .env. Разработка и деплой бота ведутся на разных машинах, и это поможет не переписывать его при переходе, например, с macOS на Linux SYSTEM_PATH:
.env
Пишем команду /start. Через неё пользователь будет попадать к первому одноименному обработчику, который проверит наличие человека в базе данных и запросит телефон, если человек новый:
Функция ask_phone выглядит следующим образом:
Функция get_phone() захватит телефон, имя и Telegram ID и запишет это в базу SQLite:
Опросник
Импортируем необходимые библиотеки. По мере раскомментирования кода станет понятно, для чего нужна каждая из них:
Чтобы попасть в саму анкету, пользователь будет нажимать клавишу «Поехали» (первую в списке, то есть нулевую по канонам ЯП) и хэндлер analyst_start примет «это на свой счёт»:
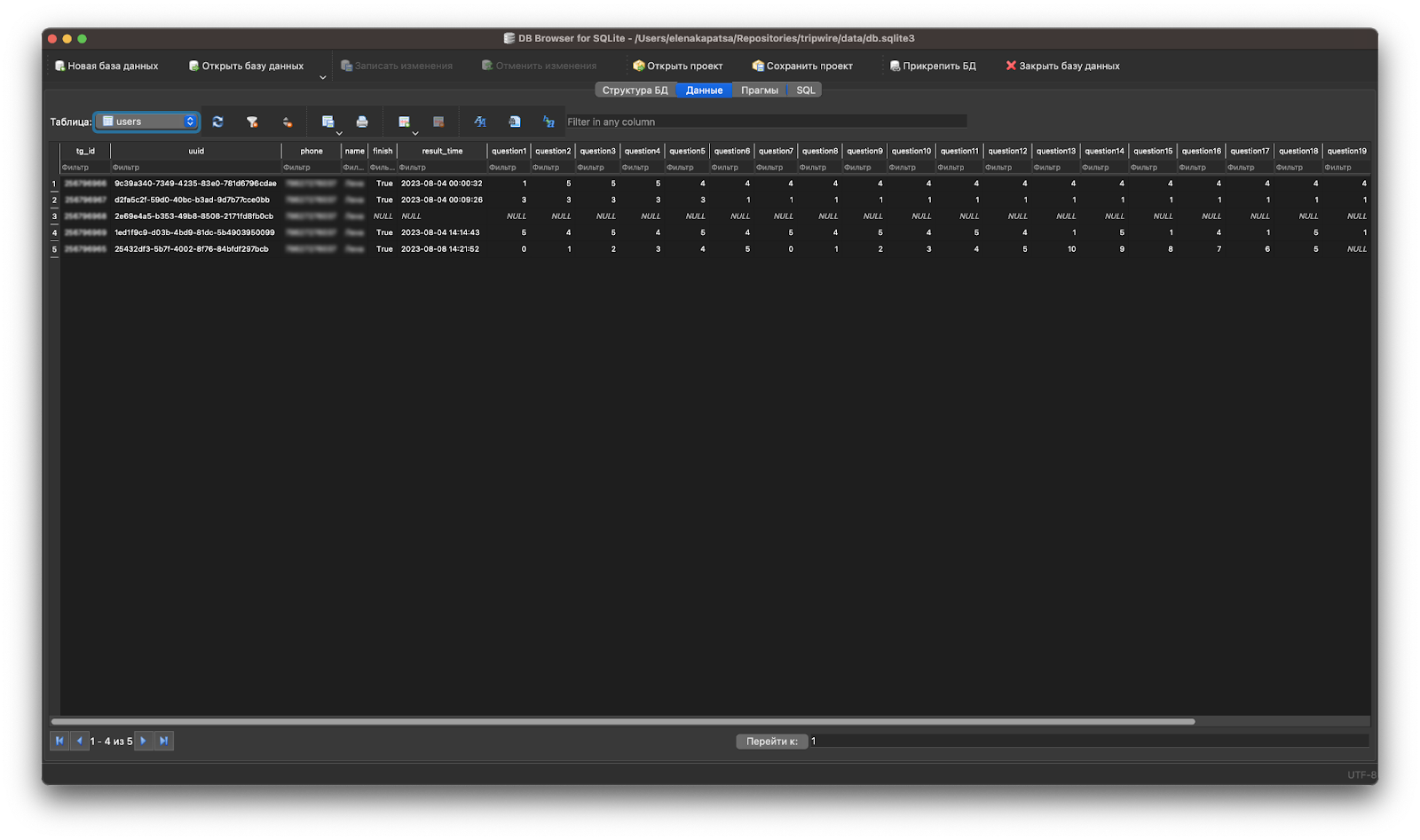
База SQLite выглядит так (для просмотра пользуюсь DB Browser for SQLite):
Заключение
Чтобы сохранить простоту восприятия, я разделила разбор кода на части. В этой мы узнали, как запустить бота в режиме разработки, как общаться с BotFather, как запрашивать пользовательские данные и записывать их. В следующей статье я расскажу, как рассчитываются паутинка, итоговое количество очков и рекомендация курса. И покажу, как выгружать базу игроков в Google Таблицы.
Если вы захотите форкнуть такого бота, то вот ссылка на репозиторий.



Добавить комментарий